Datenvisualisierung ist ein wichtiger Schritt in der Analyse neurowissenschaftlicher Daten. Das grafische Darstellen von Informationen dient dazu die Datenkomplexität zu reduzieren und wichtige Eigenschaften herauszuheben und zusammenzufassen.
Dabei geht es nicht nur darum Ergebnisse zu kommunizieren, sondern auch dazu Einsichten über die Daten zu gewinnen: Auch wenn in den meisten wissenschaftlichen Artikeln nur wenige Grafiken gezeigt werden, wurden die Daten oft während der Analyse zahlreiche Male visualisiert.
Wir schauen uns drei Kernaufgaben der Datenvisualisierung an:
Diagnostik: Daten untersuchen
Analyse: Daten zusammenfassen
Kommunikation: Forschungsergebnisse visualisieren
Je nachdem welchem Zweck eine Grafik dienen soll, müssen andere Grafikeigenschaften berücksichtigt werden. Diagnostische Grafiken müssen beispielsweise nicht in erster Linie ästhetisch ansprechend sein, sondern aufzeigen, wo Probleme im Datensatz vorliegen könnten. Eine “gute” Grafik komprimiert die Information in den Daten so, dass Erkenntnisse gewonnen werden können.
Hands-on: Visualisierungen Random Dot Daten
Das Projekt mit Daten und Code für die untenstehenden Grafiken können Sie hier herunterladen. Die Daten stammen von unserem Random Dot Experiment. Im Projekt wird mit einem R-Markdown-File gearbetet: So kann Code und Text verbunden werden, und Code-Outputs z.B. Grafiken können inline angezeigt werden, zudem ermöglicht es reproduzierbare Grafiken.
Der Ordner muss entzippt werden, um darin zu arbeiten.
In diesem Projekt, können Sie in das R-Markdown-File den untenstehenden Code kopieren und modifizieren, um die Datenvisualisierungen nachzuvollziehen und damit zu üben.
# A tibble: 10 × 8
id trial direction condition corrAns resp corr rt
<fct> <dbl> <fct> <fct> <fct> <fct> <dbl> <dbl>
1 sub-10209782 1 left speed left right 0 5.88
2 sub-10209782 2 right speed right right 1 0.822
3 sub-10209782 3 left speed left left 1 0.935
4 sub-10209782 4 right speed right right 1 0.745
5 sub-10209782 5 right speed right right 1 1.51
6 sub-10209782 6 left speed left left 1 0.940
7 sub-10209782 7 right speed right right 1 1.64
8 sub-10209782 8 left speed left left 1 2.17
9 sub-10209782 9 right speed right right 1 1.38
10 sub-10209782 10 left speed left left 1 1.55
Diagnostik: Daten untersuchen
Datensätze können sehr komplex sein, deshalb ist die Visualisierung der Daten ein hilfreicher erster Schritt. Mit Hilfe von Visualisierungen können Aussagen über die Qualität der Daten gemacht werden, z.B. über:
Fehlende Werte
Aufgabenschwierigkeit
Extreme Datenpunkte (Ausreisser)
Zeitverläufe
Verteilung der Daten
Diagnostische Grafiken dienen dazu, rasch an Informationen zu können und Probleme in Datensätzen zu entdecken. Die Grafiken müssen daher nicht ästhetisch ansprechend oder für Aussenstehende verständlich sein. Im Sinne der Reproduzierbarkeit lohnt es sich, aber auch diese Visualisierungen gut zu dokumentieren.
Im Folgenden schauen wir uns Beispiele für diagnostische Grafiken an.
Fehlende Werte
Hierbei ist es wichtig, vor allem systematisch fehlende Datenpunkte zu entdecken: Fehlt bei einer Person die Hälfte der Antworten? Möchten wir diese ausschliessen?
Diese können mit dem Package naniar relativ schnell sichtbar gemacht werden.
Was sehen Sie in der Grafik? (Wie viele Datenpunkte fehlen? In welchen Variablen?)
Um mehr über die fehlenden Werte zu erfahren, können wir uns die betroffenen Zeilen anschauen. Das kann direkt im Datensatz betrachtet werden oder indem eine zusätzliche Variable mit naniar erstellt wird, die angibt ob in dieser Zeile missings vorliegen:
# A tibble: 6 × 9
id trial direction condition corrAns resp corr rt any_missing
<fct> <dbl> <fct> <fct> <fct> <fct> <dbl> <dbl> <chr>
1 sub-16853779 1 right accuracy right right 1 NA Missing
2 sub-16853779 2 left accuracy left left 1 NA Missing
3 sub-16853779 3 right accuracy right left 0 NA Missing
4 sub-16853779 4 left accuracy left right 0 NA Missing
5 sub-16853779 5 right accuracy right right 1 NA Missing
6 sub-16853779 6 left accuracy left left 1 NA Missing
Was könnte die Ursache für die Missings sein?
Was ist zu tun?
Fehlende Werte
Je nachdem wie die fehlenden Werte zustande gekommen sind, gehen wir anders vor. Ein Ansatz könnte sein, dass wir die Trials, die keine Reaktionszeiten enthalten rauslöschen:
Wir löschen die Datenpunkte nie aus den Rohdaten, sondern nur aus dem aktuell geladenen Datensatz, den wir für die Analysen verwenden. So können wir uns immer noch umentscheiden und verlieren nicht die Information, welche Daten gefehlt haben.
Dadurch, dass wir die Datenverarbeitung in reproduzierbarem Code geschrieben haben, konnten wir überprüfen, ob ein Fehler in unserer Datenverarbeitung zu den missings geführt hat und diesen evtl. korrigieren.
Es macht nicht immer Sinn die Trials mit missing data zu löschen! Dies muss von Fall zu Fall entschieden werden. Wenn Versuchspersonen zum Beispiel teilweise zu lange brauchten um eine Aufgabe zu lösen, dann ist das eine wichtige Information, wird diese rausgelöscht, wird die Leistung der Versuchsperson systematisch überschätzt.
Wir berechnen nur für die kommenden Grafiken die Anzahl Trials pro Person, die accuracy, sowie die mittlere Reaktionszeit (wie im Kapitel Aggregierte Statistiken beschrieben).
Wir schliessen vorher alle Reaktionszeiten unter 100ms und über 10 Sekunden aus.
# zu schnelle und zu langsame Antworten ausschliessend<-d|>filter(rt>0.09&rt<15)# Daten gruppieren: Anzahl Trials, Accuracy und mittlere Reaktionszeit berechnenacc_rt_individual<-d|>group_by(id, condition)|>summarise( N =n(), ncorrect =sum(corr), accuracy =mean(corr), median_rt =median(rt))
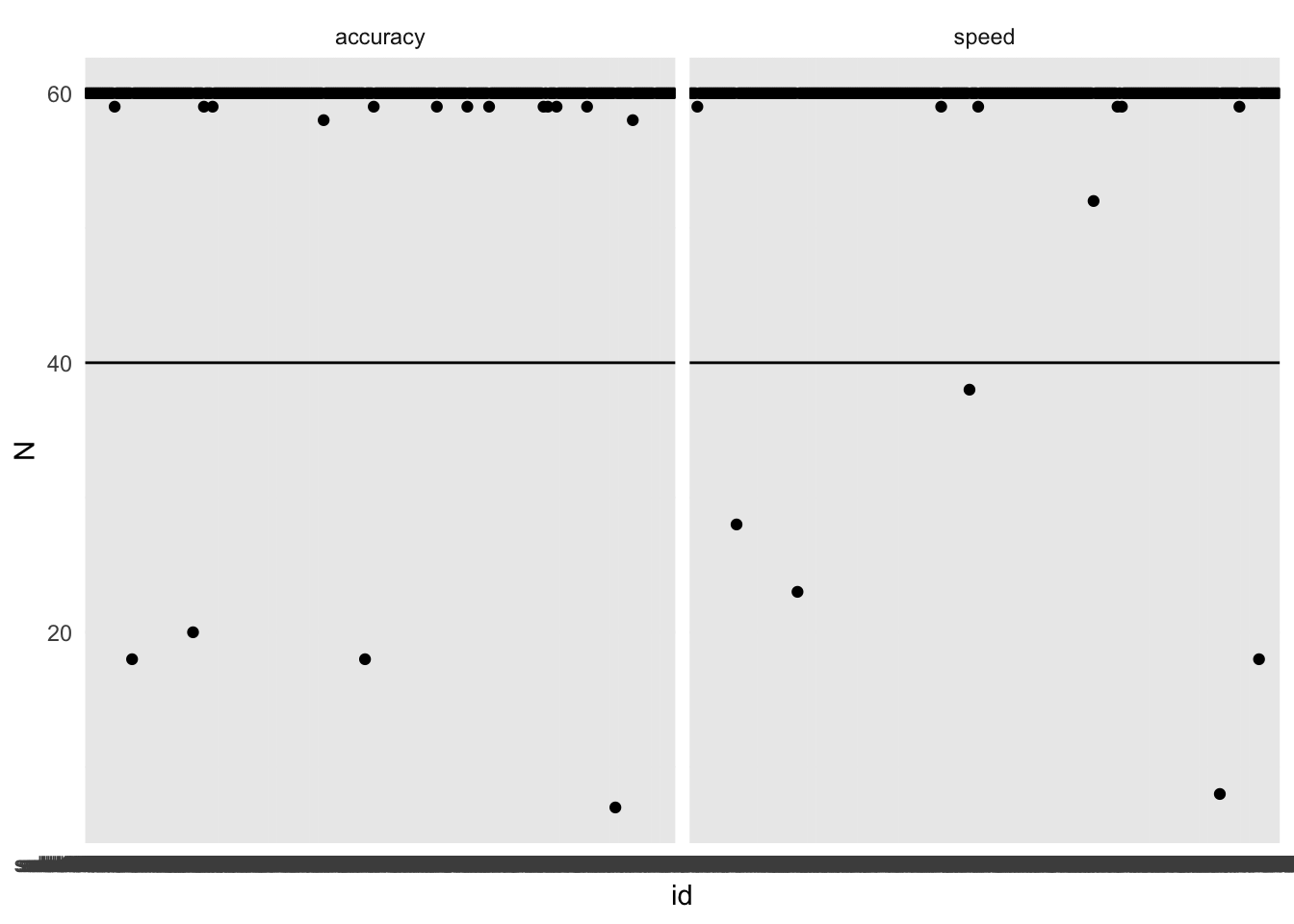
Nachdem wir Trials ohne Antwort ausgeschlossen haben, interessiert es uns, wie viele Trials jede Versuchsperson gelöst hat:
# Plot: Anzahl Trials pro Bedingung für jede Versuchsperson acc_rt_individual|>ggplot(aes(x =id, y =N))+geom_point()+facet_wrap(~condition)+geom_hline(yintercept =40)+# Horizontale Linie einfügentheme_minimal()
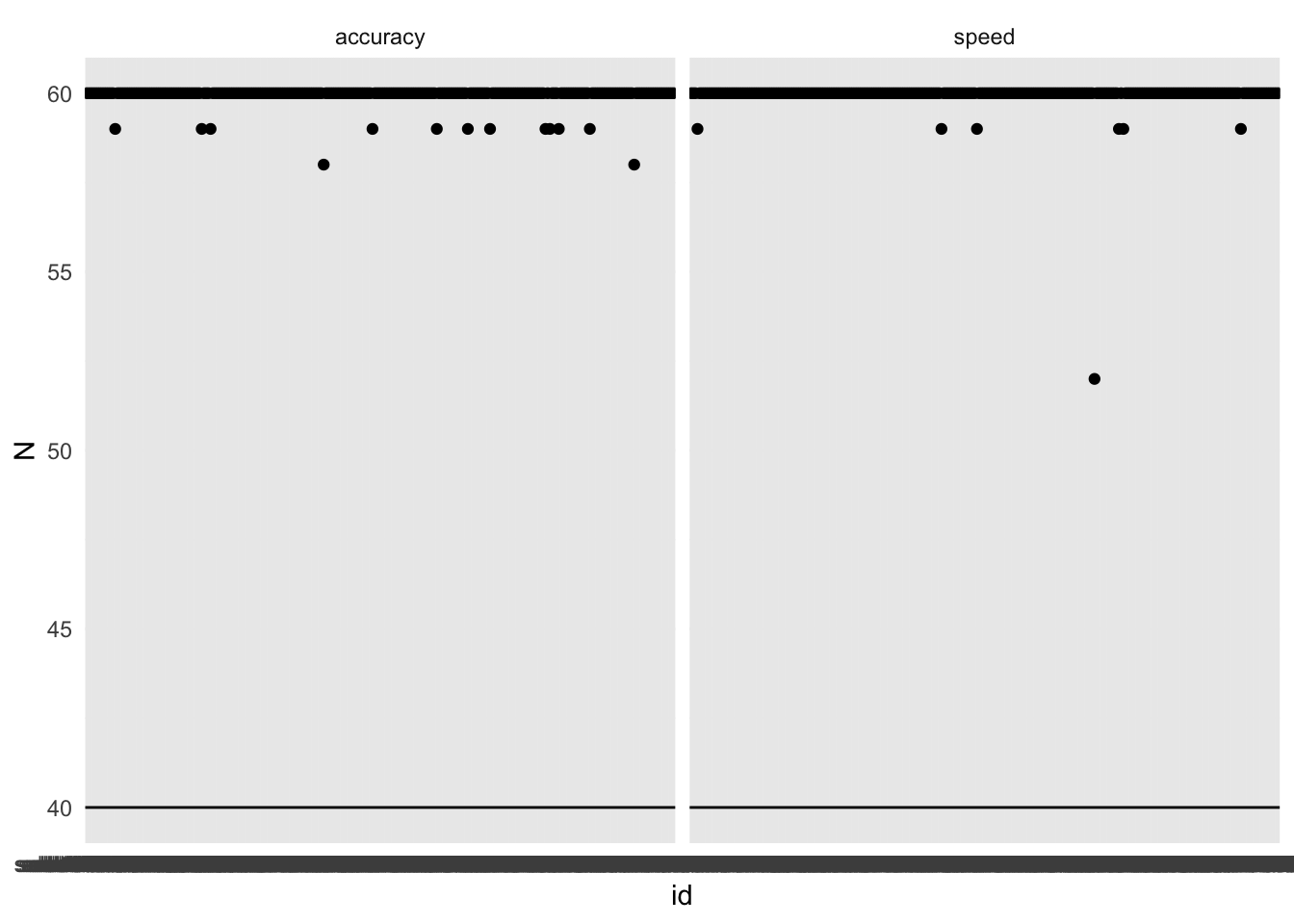
Wir schliessen alle Personen aus, die weniger als 40 gültige Trials hatten
# Datensatz mit allen Ids, welche zuwenig Trials hattenn_exclusions<-acc_rt_individual|>filter(N<40)# Aus dem Hauptdatensatz diese Ids ausschliessend<-d|>filter(!id%in%n_exclusions$id)# Checkd_acc_rt_individual<-d|>group_by(id, condition)|>summarise( N =n(), ncorrect =sum(corr), accuracy =mean(corr), median_rt =median(rt))
`summarise()` has grouped output by 'id'. You can override using the `.groups`
argument.
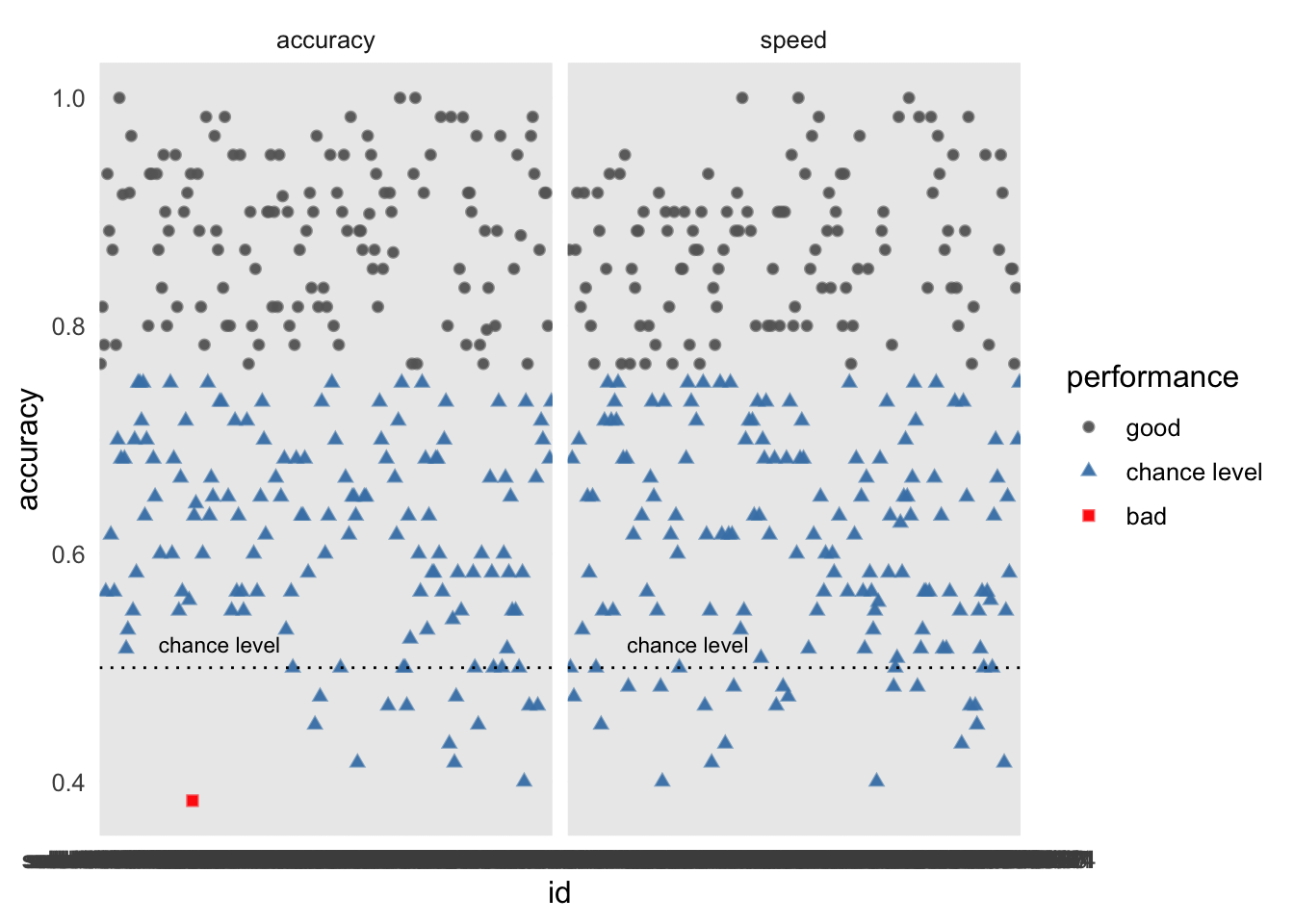
Wir können Visualisierungen auch verwenden, um extreme Datenpunkte zu identifizieren. Dafür teilen wir hier die Accuracywerte in 3 Gruppen ein und plotten diese:
# Trials nach accuracy einteilend_acc_rt_individual_grouped<-d_acc_rt_individual%>%mutate( performance =case_when(accuracy>0.75~"good",accuracy<0.4~"bad",TRUE~"chance level")%>%factor(levels =c("good", "chance level", "bad")))# Outlier visualisierend_acc_rt_individual_grouped%>%ggplot(aes(x =id, y =accuracy, color =performance, shape =performance))+geom_point(size =2, alpha =0.6)+geom_point(data =filter(d_acc_rt_individual_grouped, performance!="OK"), alpha =0.9)+facet_grid(~condition)+scale_color_manual(values =c("gray40", "steelblue", "red"))+geom_hline(yintercept =0.5, linetype='dotted', col ='black')+annotate("text", x ="sub-36817827", y =0.5, label ="chance level", vjust =-1, size =3)+theme_minimal(base_size =12)
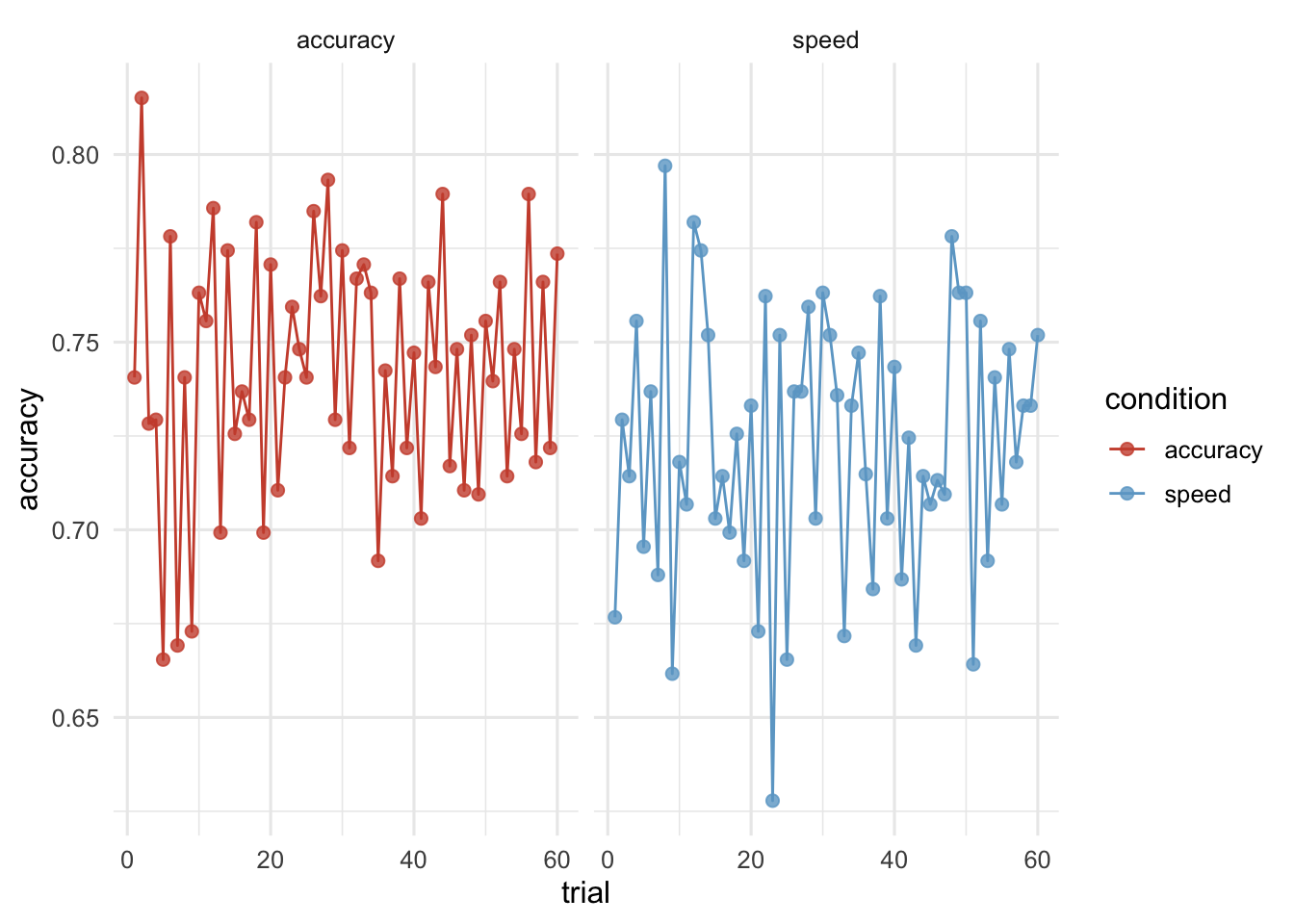
Verlaufseffekte: Ermüdung und Lernen
Verlaufseffekte können uns interessieren, weil wir starke Ermüdungs- oder Lerneffekte ausschliessen möchten. Sie könnten aber auch inhaltlich interessant sein.
In unserem Experiment möchten wir sicher sein, dass die Performanz sich über die Zeit hinweg nicht zu stark verändert. Hierzu können wir beispielsweise die accuracy in den beiden Blöcken plotten:
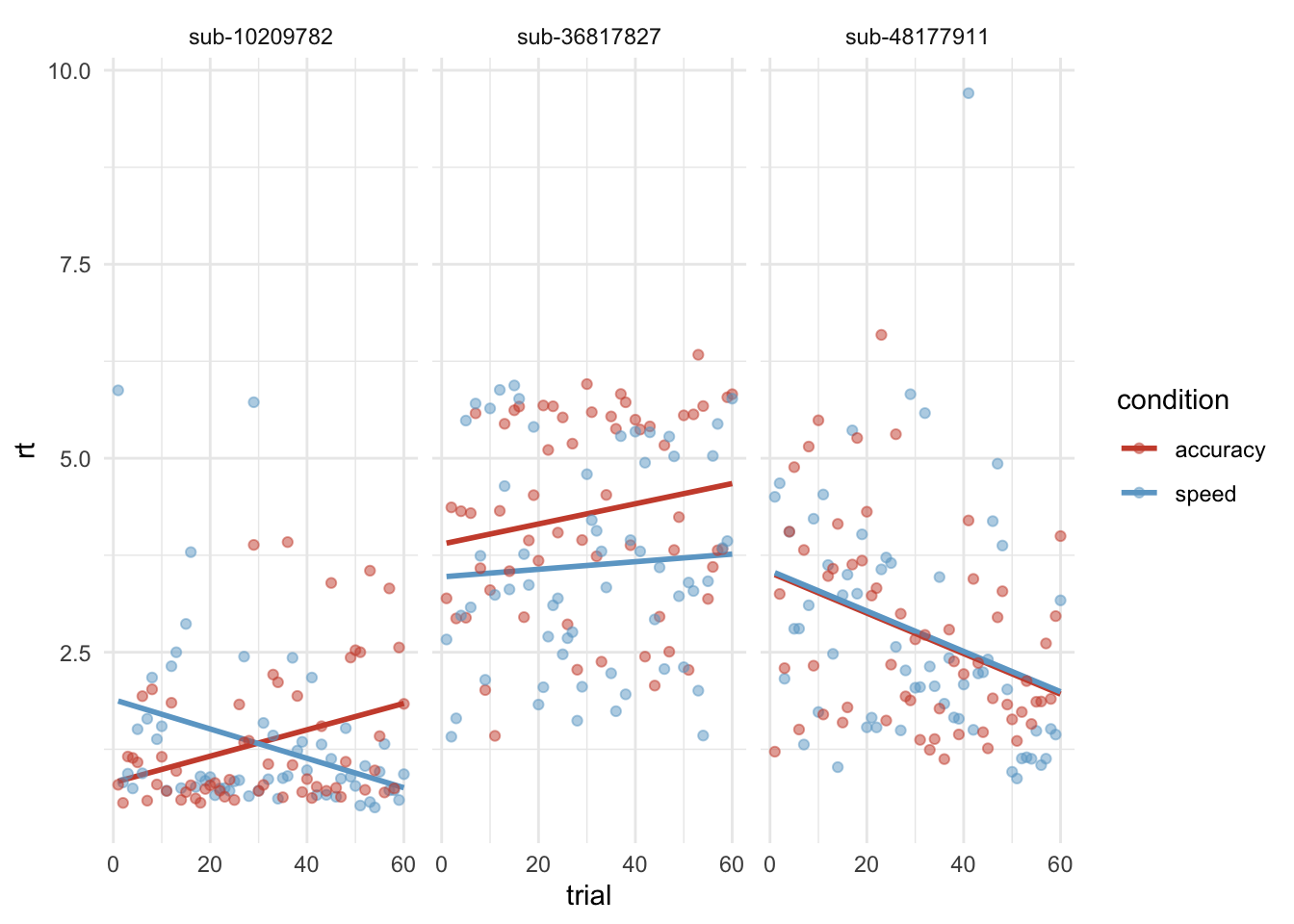
# Plot: Reaktionszeit über die Trials hinweg (für 3 Versuchspersonen)d|>filter(id%in%c("sub-10209782", "sub-36817827", "sub-48177911"))|>ggplot(aes(x =trial, y =rt, color =condition))+geom_smooth(method ="lm", se =FALSE)+geom_point(alpha =0.5)+scale_color_manual(values =c(accuracy ="tomato3", speed ="skyblue3"))+facet_wrap(~id)+theme_minimal()
Aufgabenschwierigkeit und Performanz der Versuchspersonen
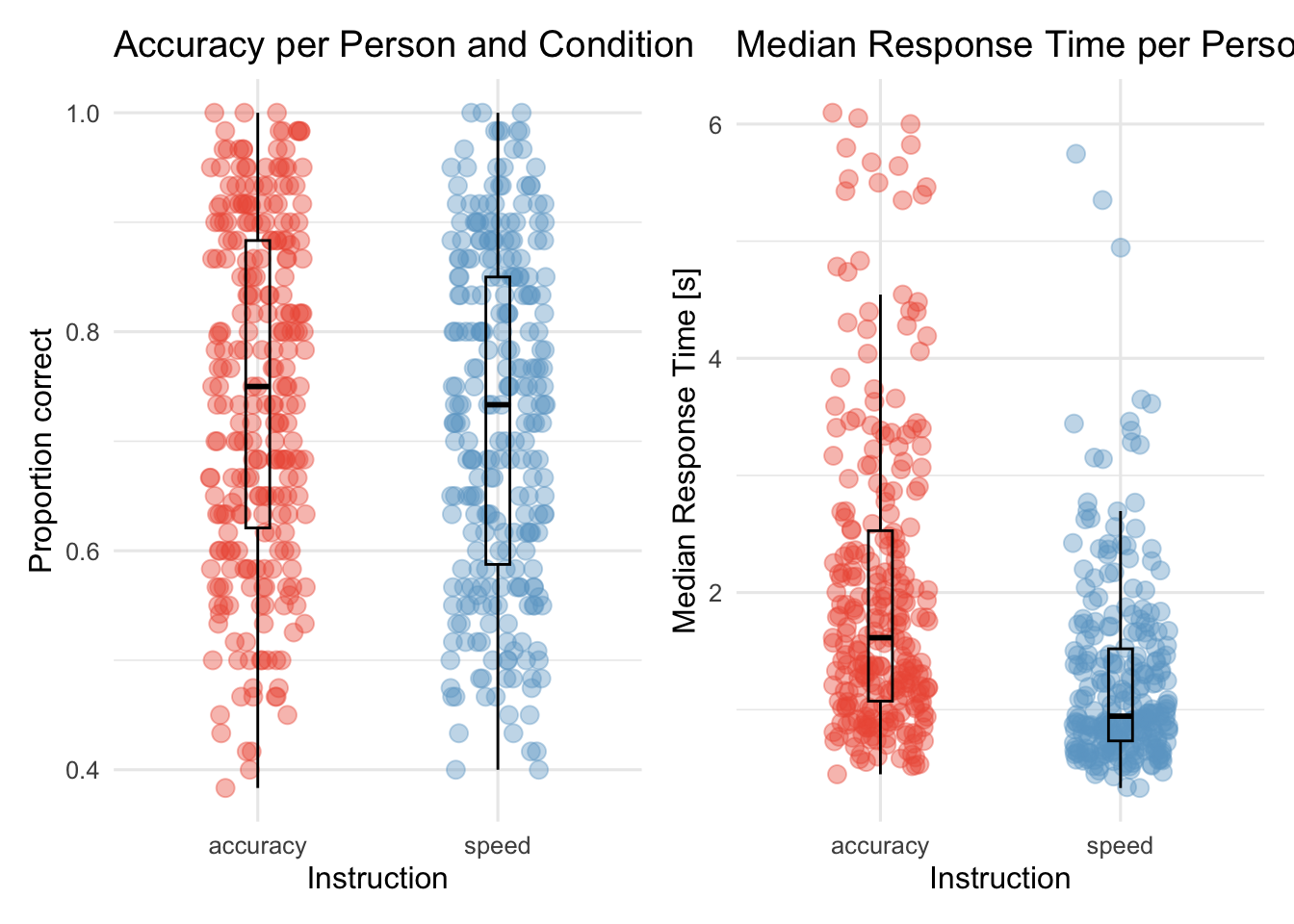
Bevor wir die Daten analysieren, möchten wir wissen, ob die Personen die Aufgabe einigermassen gut lösen konnten (und wollten). In unserem Experiment erwarten wir eine Genauigkeit (accuracy) über dem Rateniveau von 50%. Wir plotten hierfür die accuracy für jede Person und Bedingung.
# Plot accuracy per person and conditionp1<-d_acc_rt_individual|>ggplot(aes(x =condition, y =accuracy, color =condition))+geom_jitter(size =3, alpha =0.4, width =0.2, height =0)+geom_boxplot(width =0.1, alpha =0, color ="black")+scale_color_manual(values =c(accuracy ="tomato2", speed ="skyblue3"))+labs(x ="Instruction", y ="Proportion correct", title ="Accuracy per Person and Condition")+theme_minimal(base_size =12)+theme(legend.position ="none")p2<-d_acc_rt_individual|>ggplot(aes(x =condition, y =median_rt, color =condition))+geom_jitter(size =3, alpha =0.4, width =0.2, height =0)+geom_boxplot(width =0.1, alpha =0, color ="black")+scale_color_manual(values =c(accuracy ="tomato2", speed ="skyblue3"))+labs(x ="Instruction", y ="Median Response Time [s]", title ="Median Response Time per Person and Condition")+theme_minimal(base_size =12)+theme(legend.position ="none")library(patchwork)p1+p2
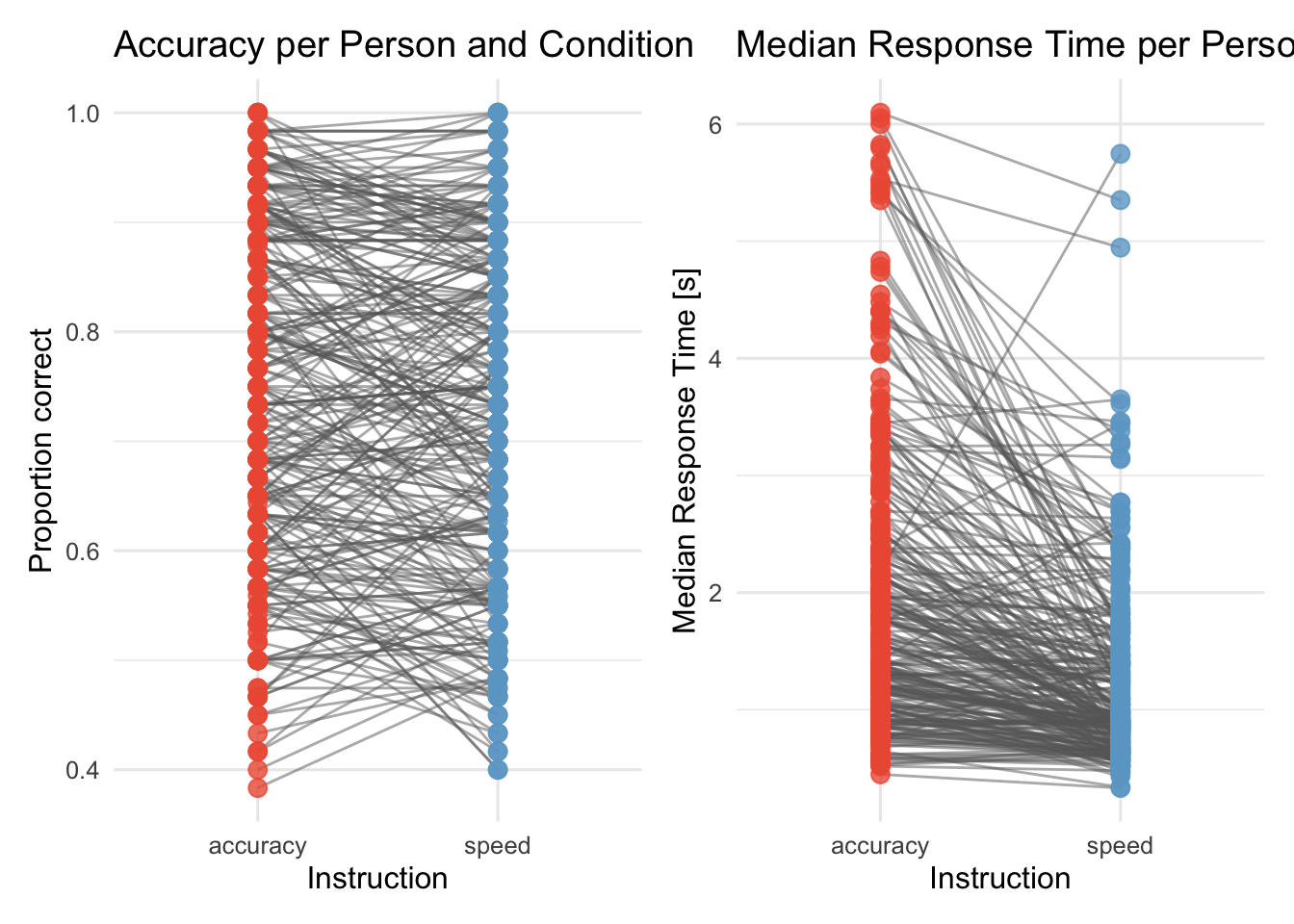
Und wir interessieren uns, wie sich die accuracy zwischen den Bedingungen unterscheidet. Das zeigt uns, ob die Instruktion eine Wirkung hatte. Dafür fügen wir Linien ein, die die accuracy- Werte pro Versuchsperson verbindet:
p3<-d_acc_rt_individual|>ggplot(aes(x =condition, y =accuracy, color =condition, group =id))+geom_line(color ="grey40", alpha =0.5)+geom_jitter(size =3, alpha =0.8, width =0, height =0)+scale_color_manual(values =c(accuracy ="tomato2", speed ="skyblue3"))+labs(x ="Instruction", y ="Proportion correct", title ="Accuracy per Person and Condition")+theme_minimal(base_size =12)+theme(legend.position ="none")p4<-d_acc_rt_individual|>ggplot(aes(x =condition, y =median_rt, color =condition, group =id))+geom_line(color ="grey40", alpha =0.5)+geom_jitter(size =3, alpha =0.8, width =0, height =0)+scale_color_manual(values =c(accuracy ="tomato2", speed ="skyblue3"))+labs(x ="Instruction", y ="Median Response Time [s]", title ="Median Response Time per Person and Condition")+theme_minimal(base_size =12)+theme(legend.position ="none")p3+p4
Hands-on: Datenqualität
Besprechen Sie miteinander, was Sie nun über unsere Daten wissen.
Haben die Versuchspersonen die Aufgaben lösen können?
War die Aufgabe zu einfach, zu schwierig?
Denken Sie, die Personen waren motiviert?
Welche Datensätze / Trials möchten wir ausschliessen? (Dies müsste eigentlich vor dem Anschauen der Daten entschieden werden, um zu verhindern, dass man Datenpunkte ausschliesst, welche die Hypothese nicht bestätigen.)
Wie gut eignen sich die Daten, um die Forschungsfrage zu beantworten?
Was könnte bei einem nächsten Experiment besser gemacht werden?
Analyse: Daten zusammenfassen und explorieren
Grafiken können einerseits eine Ergänzung zur statistischen Datenanalyse sein, wie auch die Resultate der Analysen (bspw. geschätzte Parameterwerte) visualisieren. Sie haben den Vorteil, dass Informationen über Daten oder Analyseergebnisse gleichzeitig ersichtlich sind, sie können also vom Betrachtenden direkt verglichen werden.
Wir möchten die Daten hinsichtlich der Forschungsfragen visualisieren. Die Grafiken müssen vor allem präzise und informativ sein. Um Schlüsse aus Daten ziehen zu können, müssen diese zusammengefasst werden. Dazu eignen sich Masse der zentralen Tendenz, also beispielsweise der Mittelwert, Median oder Modus. Gleichzeitig ist es wichtig, dass auch Verteilungsmasse berichtet werden, wie Standardabweichungen oder Standardfehler. Wir können auch mit Modellen berechnete Werte wie Parameterschätzungen und Konfidenzintervalle grafisch darstellen.
Mit Hilfe von Visualisierungen können z.B. Aussagen können gemacht werden über:
Verteilung der Daten
Zusammenhänge von Variablen (Korrelationen, Zeitverläufe)
Vergleiche und Unterschiede von Gruppen / Bedingungen
Verteilung der Rohdaten
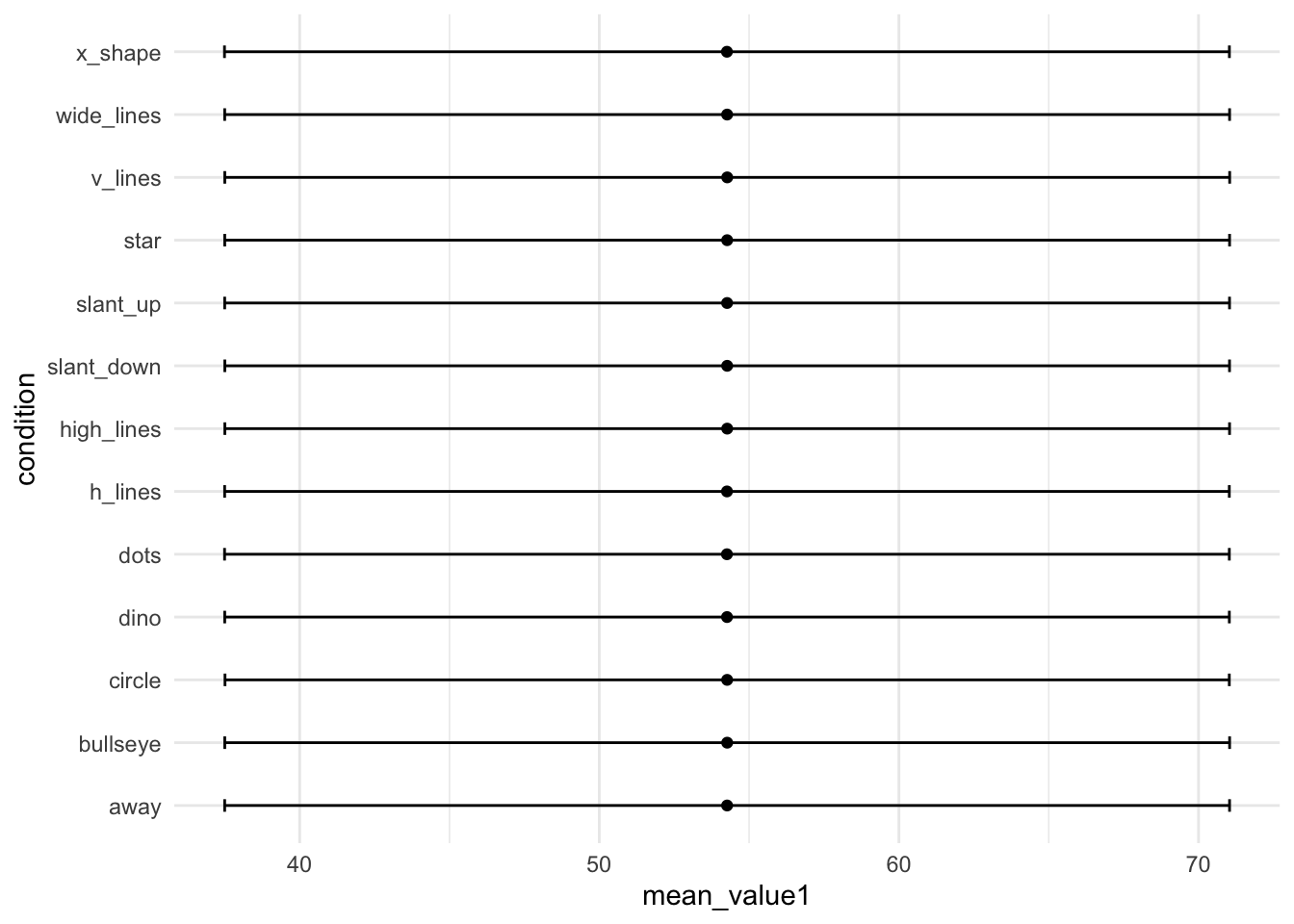
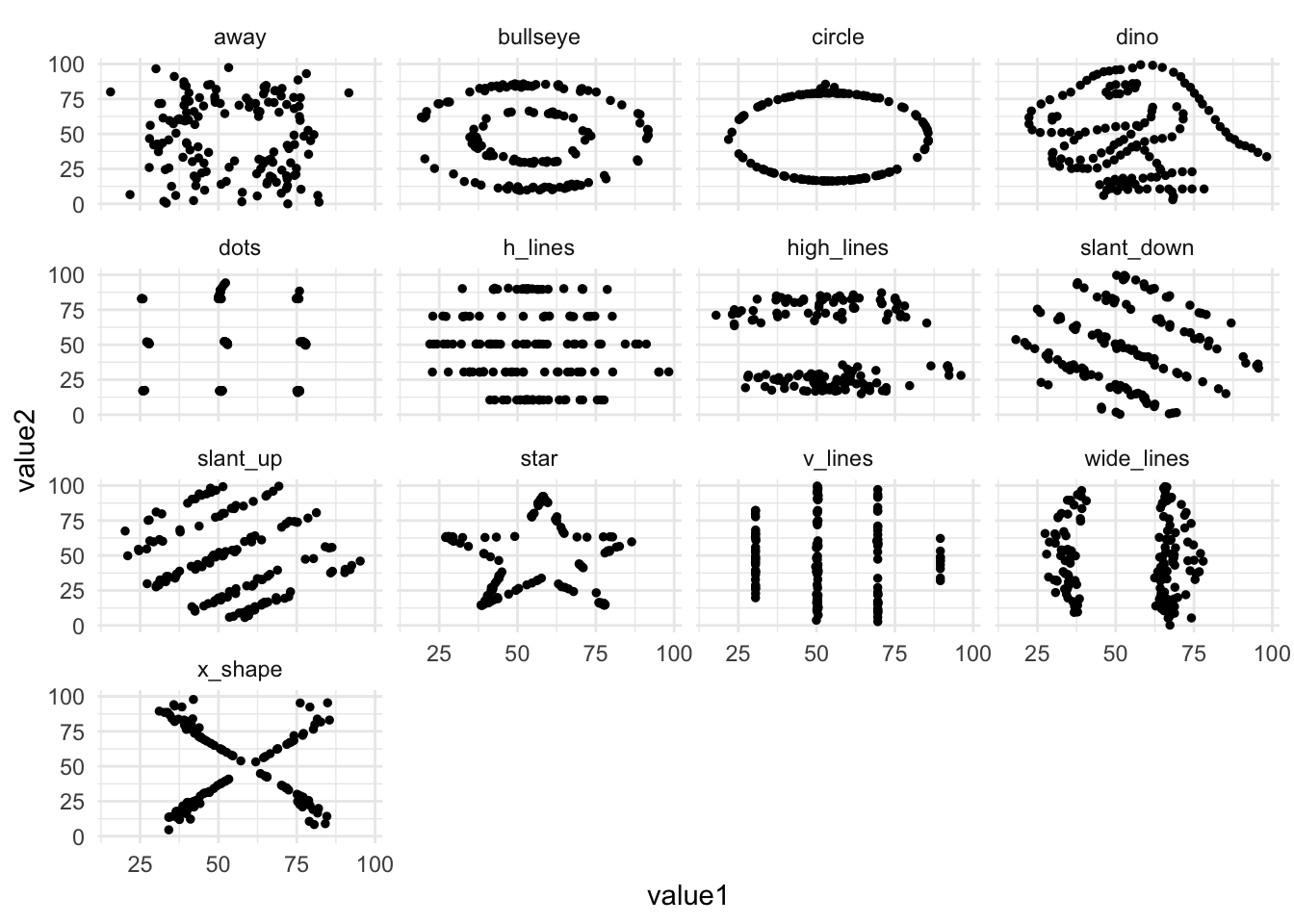
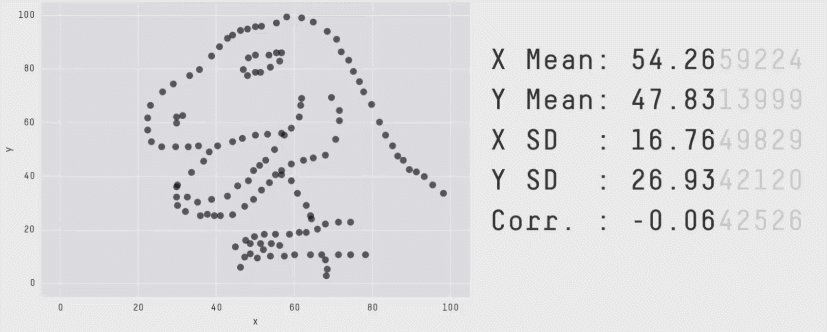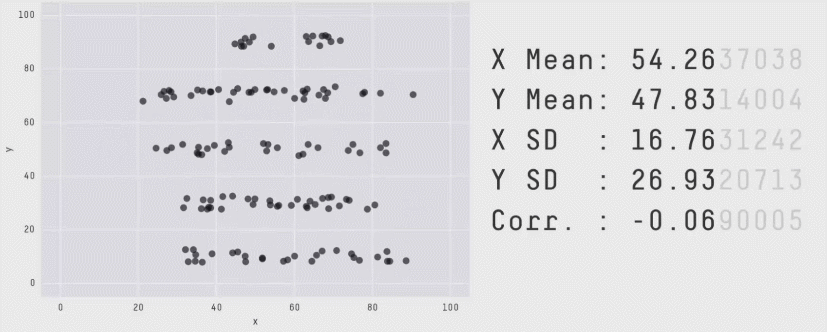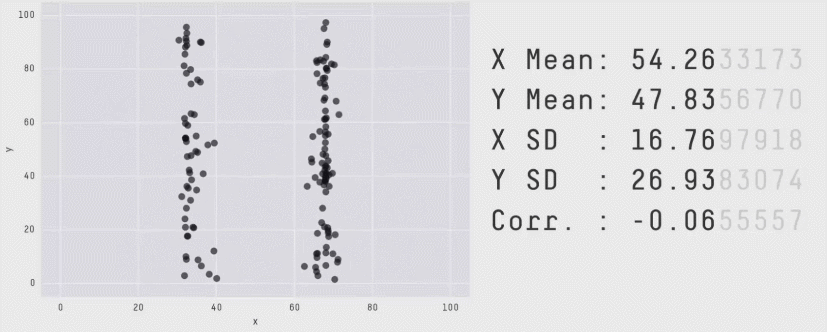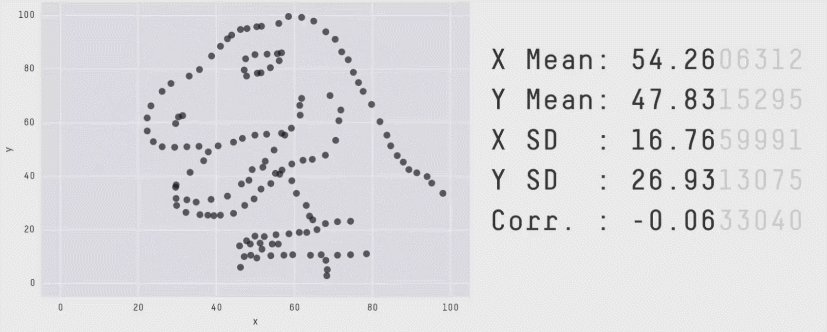
Daten von neurowissenschaftlichen Studien können wichtige Informationen enthalten, die ohne Grafiken übersehen werden können (Rousselet, Pernet, and Wilcox (2017)). Das Visualisieren kann Muster zum Vorschein bringen, die durch statistische Auswertungen nicht sichtbar sind. Die Wichtigkeit von Datenvisualisierung für das Entdecken von Mustern in den Daten zeigte Francis Anscombe 1973 mit dem Anscombe’s Quartet. Dies diente als Inspiration für das Erstellen des “künstlichen” Datensatzes DatasaurusDozen, welchen wir in der letzten Veranstaltung visualisiert haben. Verschiedene Rohwerte, können dieselben Mittelwerte, Standardabweichungen und Korrelationen ergeben. Nur wenn man die Rohwerte plottet erkennt man, wie unterschiedlich die Datenpunkte verteilt sind.
Dies wird ersichtlich, wenn wir die Mittelwerte und Standardabweichungen für jede Gruppe berechnen und plotten:
# load DatasaurusDozen datasetdino_data<-read.csv("data/DatasaurusDozen.csv")%>%mutate(condition =as.factor(condition))# Plot mean and standard deviation for value 1 per condition dino_data|>group_by(condition)|>summarise(mean_value1 =mean(value1), sd_value1 =sd(value1))|>ggplot(mapping =aes(x =mean_value1, y =condition))+geom_point()+geom_errorbar(aes(xmin =mean_value1-sd_value1, xmax =mean_value1+sd_value1), width =0.2)+theme_minimal()
Masse der zentralen Tendenz sind beispielsweise der Mittelwert, der Median und Modus. Wenn wir uns dafür interessieren, wie sich die accuracy in Bezug auf alle Teilnehmenden verhält, schauen wir uns die zentrale Tendenz über alle Personen hinweg an. Es sollte nie nur die zentrale Tendenz, sondern immer auch ein passendes Verteilungsmass berichtet werden.
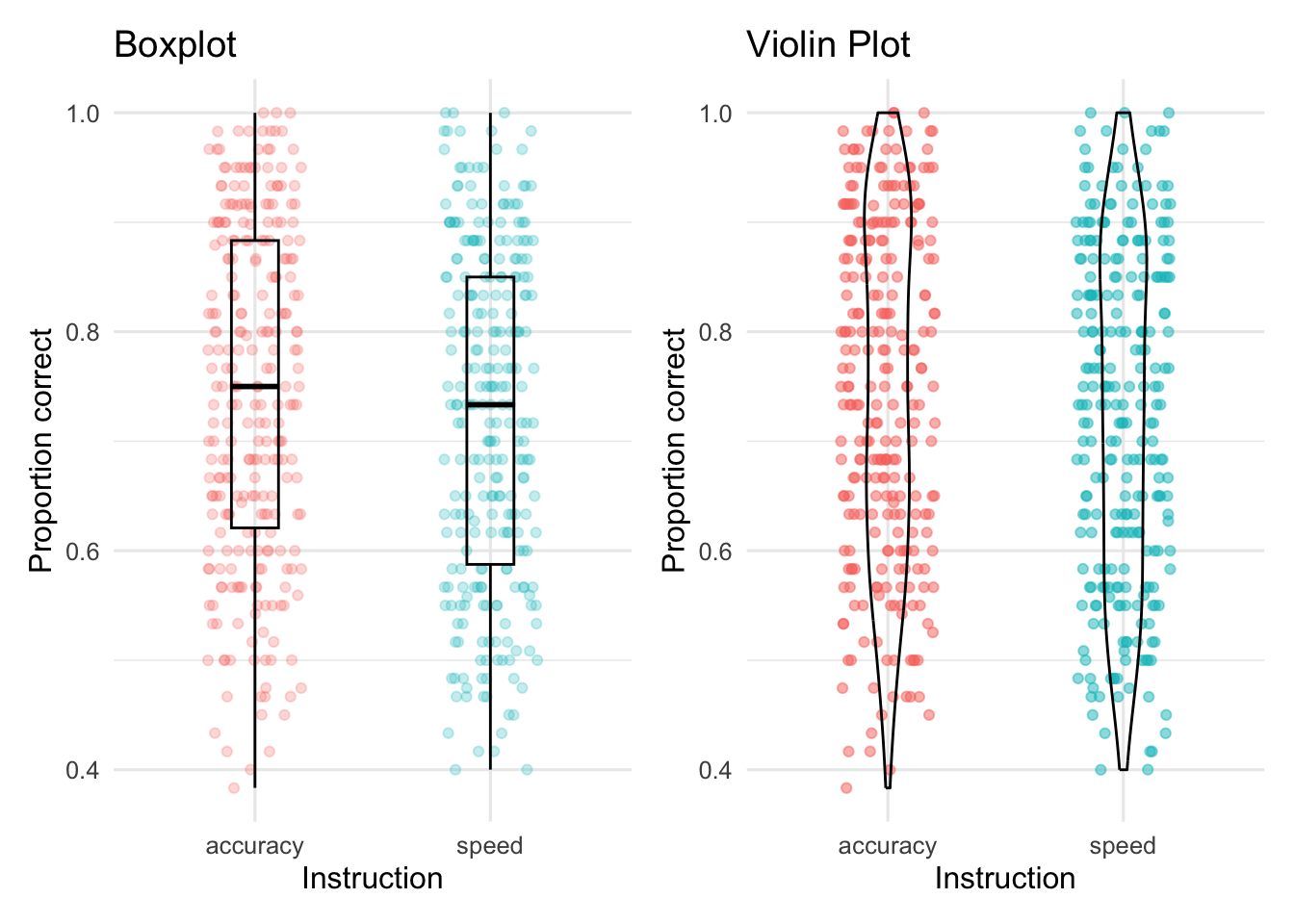
Wie oben schon gezeigt können wir dies z.B. mit Boxplots umsetzen Diese zeigen uns den Median und die Quartile sowie Ausreisser an. Eine andere Möglichkeit Verteilungen anzuzeigen sind die Violinplots. Hier wurden mit geom_jitter() auch die Mittelwerte der einzelnen Personen im Plot eingefügt.
# Boxplotp_boxplot<-d_acc_rt_individual|>ggplot(aes(x =condition, y =accuracy, color =condition))+geom_jitter(alpha =0.25, width =0.2)+geom_boxplot(alpha =0, width =0.2, color ="black")+scale_fill_manual(values =c(accuracy ="tomato3", speed ="skyblue3"))+labs(title ="Boxplot", x ="Instruction", y ="Proportion correct")+theme_minimal(base_size =12)+theme(legend.position ="none")# Violin Plotp_violin<-d_acc_rt_individual|>ggplot(aes(x =condition, y =accuracy, color =condition))+geom_jitter(alpha =0.5, width =0.2)+geom_violin(alpha =0, width =0.2, color ="black")+scale_fill_manual(values =c(accuracy ="tomato3", speed ="skyblue3"))+labs(title ="Violin Plot", x ="Instruction", y ="Proportion correct")+theme_minimal(base_size =12)+theme(legend.position ="none")p_boxplot+p_violin
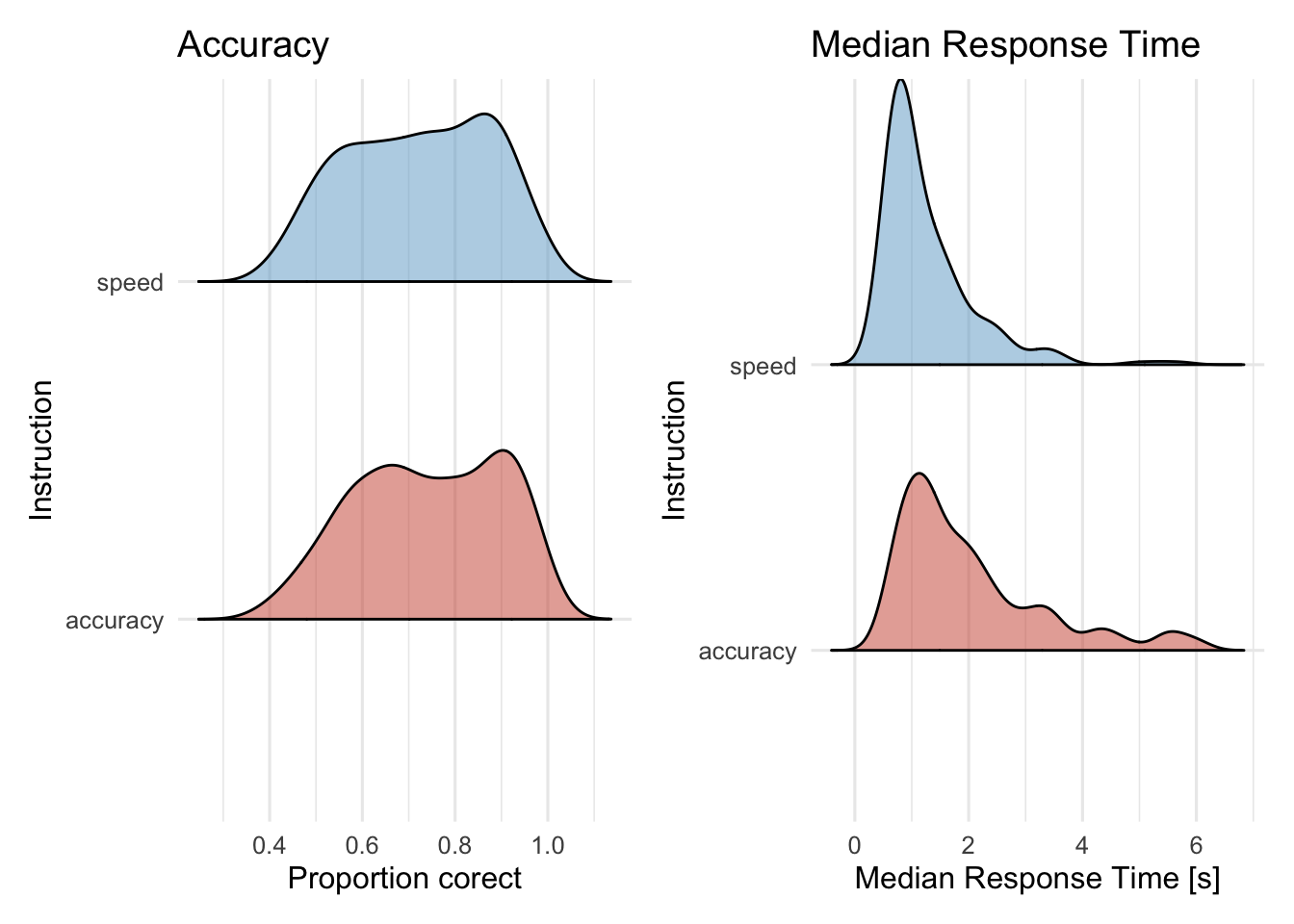
Das Packageggridges bietet die Möglichkeit die Verteilungen zu plotten. Mehr Informationen hierzu finden Sie hier in der Dokumentation.
library(ggridges)p5<-d_acc_rt_individual|>ggplot(aes(x =accuracy, y =condition, fill =condition))+geom_density_ridges2(scale =0.5, alpha =0.5)+scale_fill_manual(values =c(accuracy ="tomato3", speed ="skyblue3"))+labs(title ="Accuracy", x ="Proportion corect", y ="Instruction")+theme_minimal(base_size =12)+theme(legend.position ="none")p6<-d_acc_rt_individual|>ggplot(aes(x =median_rt, y =condition, fill =condition))+geom_density_ridges2(scale =1, alpha =0.5)+scale_fill_manual(values =c(accuracy ="tomato3", speed ="skyblue3"))+labs(title ="Median Response Time", x ="Median Response Time [s]", y ="Instruction")+theme_minimal(base_size =12)+theme(legend.position ="none")p5+p6
Aggregierte Statistiken
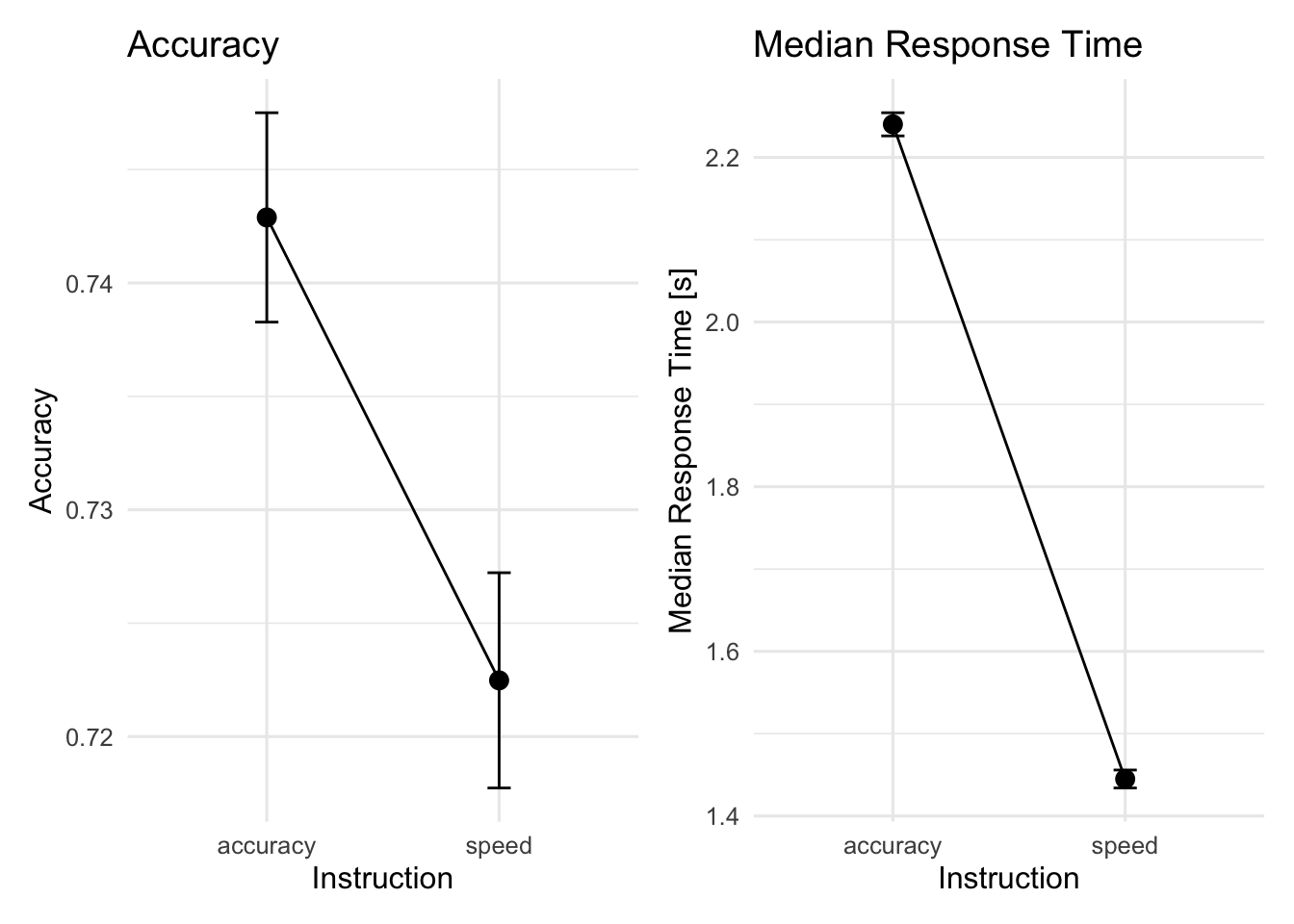
Wenn wir Mittelwerte und Standardfehler angeben möchten können wir dies wie folgt tun. Wichtig ist hier, dass wir within-subject Standardfehler berechnen. Genaueres zu den Unterschieden zwischen within- und between-subject Standardfehlern finden Sie hier. Wir verwenden das PackageRmisc, da dieses jedoch wegen der Namensgebung oft Konflikte auslöst, laden wir Rmisc nicht mit der library()-Funktion, sondern stellen es einfach vor die benötigte
d_acc_within<-d|>Rmisc::summarySEwithin(measurevar ="corr", withinvars ="condition", idvar ="id", na.rm =FALSE, conf.interval =0.95)p7<-d_acc_within|>ggplot(aes(x =condition, y =corr, group =1))+geom_line()+geom_errorbar(width =.1, aes(ymin =corr-se, ymax =corr+se))+geom_point(size =3)+labs(title ="Accuracy", x ="Instruction", y ="Accuracy")+theme_minimal(base_size =12)+theme(legend.position ="none")d_rt_within<-d|>Rmisc::summarySEwithin(measurevar ="rt", withinvars ="condition", idvar ="id", na.rm =FALSE, conf.interval =0.95)p8<-d_rt_within|>ggplot(aes(x =condition, y =rt, group =1))+geom_line()+geom_errorbar(width =.1, aes(ymin =rt-se, ymax =rt+se))+geom_point(size =3)+labs(title ="Median Response Time", x ="Instruction", y ="Median Response Time [s]")+theme_minimal(base_size =12)+theme(legend.position ="none")p7+p8
Hier finden Sie weitere Code-Beispiele für das Plotten von Verteilungsmassen.
Hier finden Sie Informationen, wie Reaktionszeiten zusammengefasst und visualisiert werden könnten.
Visualisieren von Modellschätzungen
Wenn für die statistische Analyse ein Modell geschätzt wurde, kann auch dies visualisiert werden. Auf diese Form der Visualisierung wird hier aber nicht eingegangen. Wir lernen dies im Rahmen der noch kommenden Versanstaltungen kennen.
see: Package zum Visualisieren von Statistischen Modellen
Kommunikation: Forschungsergebnisse visualisieren
Kommunikation der Ergebnisse findet vor allem in den wissenschaftlichen Artikeln, Postern oder Präsentationen statt. Bei Visualisierungen die der Kommunkation dienen sind folgende Merkmale wichtig:
Beschriftungen
Die genaue Beschriftung und deren Lesbarkeit ist für diese Form von Grafiken zentral. Achten Sie sich auf Folgendes:
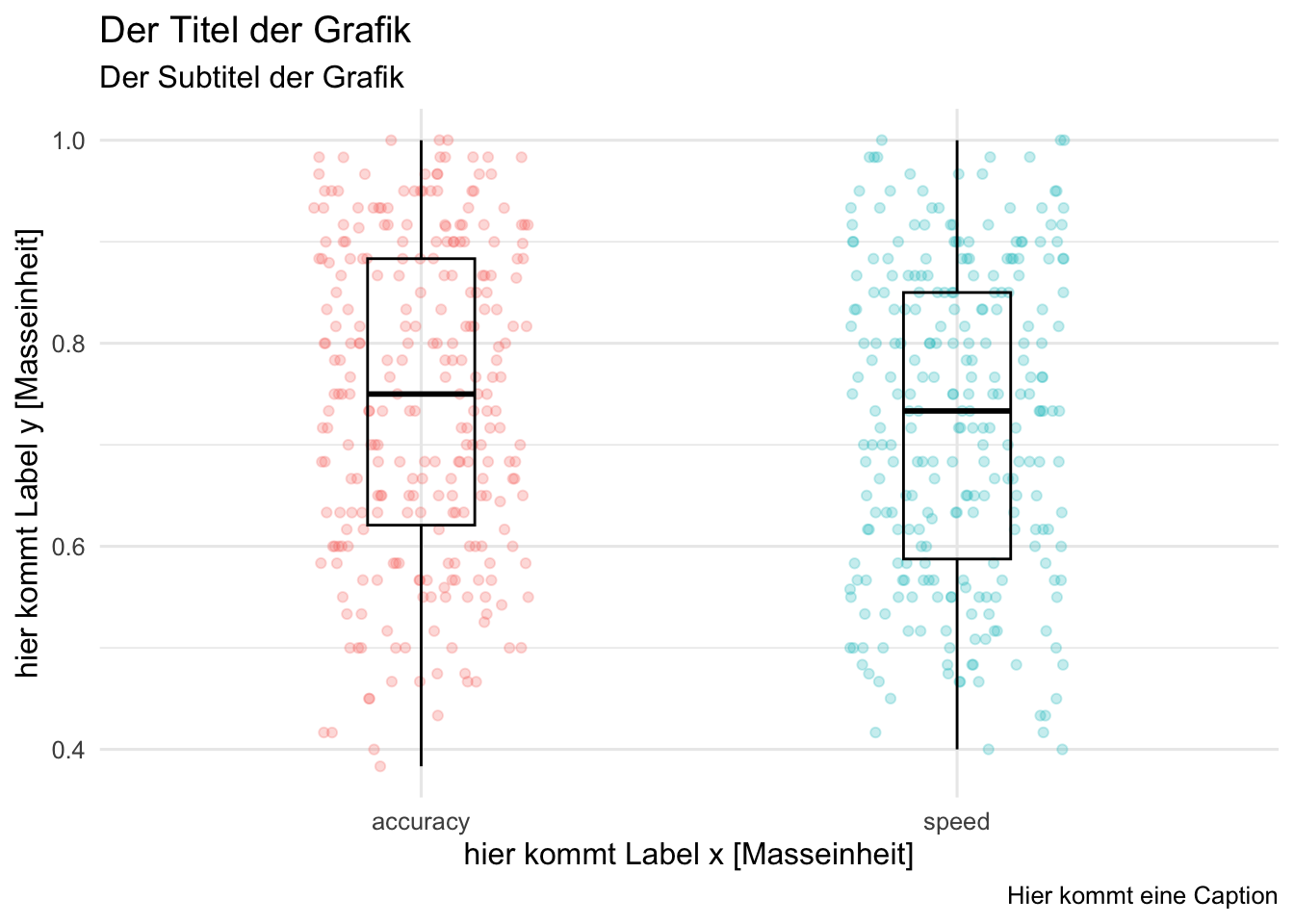
Die Achsenbeschriftungen enthalten die verwendete Variable in Klartext (nicht den R Variablennamen) und wenn zutreffend auch die Masseinheit (z.B. Response Time [ms]). Beschriftungen können Sie einfügen mit labs().
p_boxplot+labs(title ="Der Titel der Grafik", subtitle ="Der Subtitel der Grafik", x ="hier kommt Label x [Masseinheit]", y ="hier kommt Label y [Masseinheit]", caption =" Hier kommt eine Caption")
Warning: No shared levels found between `names(values)` of the manual scale and the
data's fill values.
Farben / Formen usw. werden in einer Legende den Gruppen zugeordnet (Ausnahme: wenn Daten von einzelnen Personen geplottet werden, wird die Versuchspersonennummer nicht aufgeführt).
Masse der zentralen Tendenz und Varianzmasse werden beschrieben (z.B. Standardfehler oder Standardabweichung?)
5 Merkmale einer guten Grafik
Es gibt unzählige Optionen die eigenen Daten zu visualisieren. Folgende Prinzipien helfen beim Erstellen einer informativen Grafik, die zur Kommunikation der Ergebnisse dient.
1. Eine Frage beantworten
Jede Grafik sollte mindestens eine teilweise aber auch mehrere Fragen beantworten.
👉 Welche Frage möchte ich beantworten? Welche Form der Visualisierung beantwortet diese Frage am besten?
Hierbei kann es hilfreich sein den “Arbeitstitel” der Grafik als Frage zu formulieren.
2. Zielgruppe berücksichtigen
Beim Erstellen der Grafik sollte beachtet werden, an wen sich die Grafik richtet. Für eine Präsentation müssen die Achsenbeschriftungen vergrössert und die Grafik simpel gehalten werden. In einem wissenschaftlichen Artikel kann die Grafik komplexer gestaltet werden, da die Lesenden sich mehr Zeit zum Anschauen nehmen können. Zudem sollten hier die Vorgaben des Journals berücksichtigt werden. Auch wichtig ist das Verwenden von “farbenblind-freundlichen” Palletten, rot und grün ist z.B. eine schlechte Wahl.
👉 Für welchen Zweck / für wen erstelle ich die Grafik? Wie ist das Vorwissen des Zielpublikums?
Für einen Fachartikel lohnt es sich, zu Beginn die Vorgaben der Fachzeitschrift zu berücksichtigen.
3. Die Daten zeigen
Das tönt simpel, wird aber oft nicht berücksichtigt. Bei einer Grafik geht es in erster Linie um die Daten. Es sollte die simpelste Form gewählt werden, welche die Informationen vermittelt. Oft braucht es keine ausgefallenen Grafikideen oder neuartigen Formate. Hierbei ist es wichtig, die Art der Daten zu berücksichtigen: Wie viele Variablen sind es? Sind diese kontinuierlich (z.B. Reaktionszeiten) oder diskret (z.B. Experimentalbedingungen)? Wie viele Dimensionen haben meine Daten? Mit zwei Achsen lassen sich zwei Dimensionen darstellen, zusätzlich können mit Farben und Formen noch weitere Dimensionen abgebildet werden (z.B. Millisekunden, Bedingung 1 und Bedingung 2). Es können Rohwerte geplottet werden oder summary statistics (z.B. Mittelwerte, Standardabweichungen)
👉 Welche Art Grafik eignet sich für meine Frage und meine Daten? Schauen Sie z.B. hier nach oder nutzen Sie das esquisse-Package.
Beispiele für verschiedenen Plots in R sind z.B. histogram, boxplot, violin plot, scatter plot / correlogram, jitter plot, raincloud plot, percentiles / shift functions, area chart, heat map.
4. Optimieren des data-ink ratios
Das Daten-Tinte-Verhältnis sollte so optimal wie möglich sein. Das bedeutet, das idealerweise jeder Strich, jeder Punkt, jedes Textfeld Information beinhaltet. Alles was keine Information transportiert oder nur wiederholt kann weggelassen werden.
👉 Was kann ich weglassen?
In R kann zum Schluss des Plots + theme_minimal() hinzugefügt werden, dies entfernt u.a. den grauen Hintergrund. Das Grau des Hintergrunds ist Farbe (ink), welche keine Information transportiert, das Weglassen lässt die Grafik ruhiger wirken.
5. Feedback einholen und revidieren
Das Erstellen einer guten Grafik ist iterativ, das heisst, sie wird immer wieder überarbeitet, bis sie die Information möglichst einfach, genau aber klar kommuniziert. Hierbei ist Feedback oft unerlässlich.
👉 Was denken andere über Ihre Grafik?
References
Matejka, Justin, and George Fitzmaurice. 2017. “Same Stats, DifferentGraphs: GeneratingDatasets with VariedAppearance and IdenticalStatistics Through SimulatedAnnealing.” In Proceedings of the 2017 CHIConference on HumanFactors in ComputingSystems, 1290–94. Denver Colorado USA: ACM. https://doi.org/10.1145/3025453.3025912.
Rousselet, Guillaume A., Cyril R. Pernet, and Rand R. Wilcox. 2017. “Beyond Differences in Means: Robust Graphical Methods to Compare Two Groups in Neuroscience.”European Journal of Neuroscience 46 (2): 1738–48. https://doi.org/10.1111/ejn.13610.