10. Sitzung
Evidence accumulation models: II
Neurowissenschaft Computerlab FS 22
2022-05-03
Grafisch darstellen
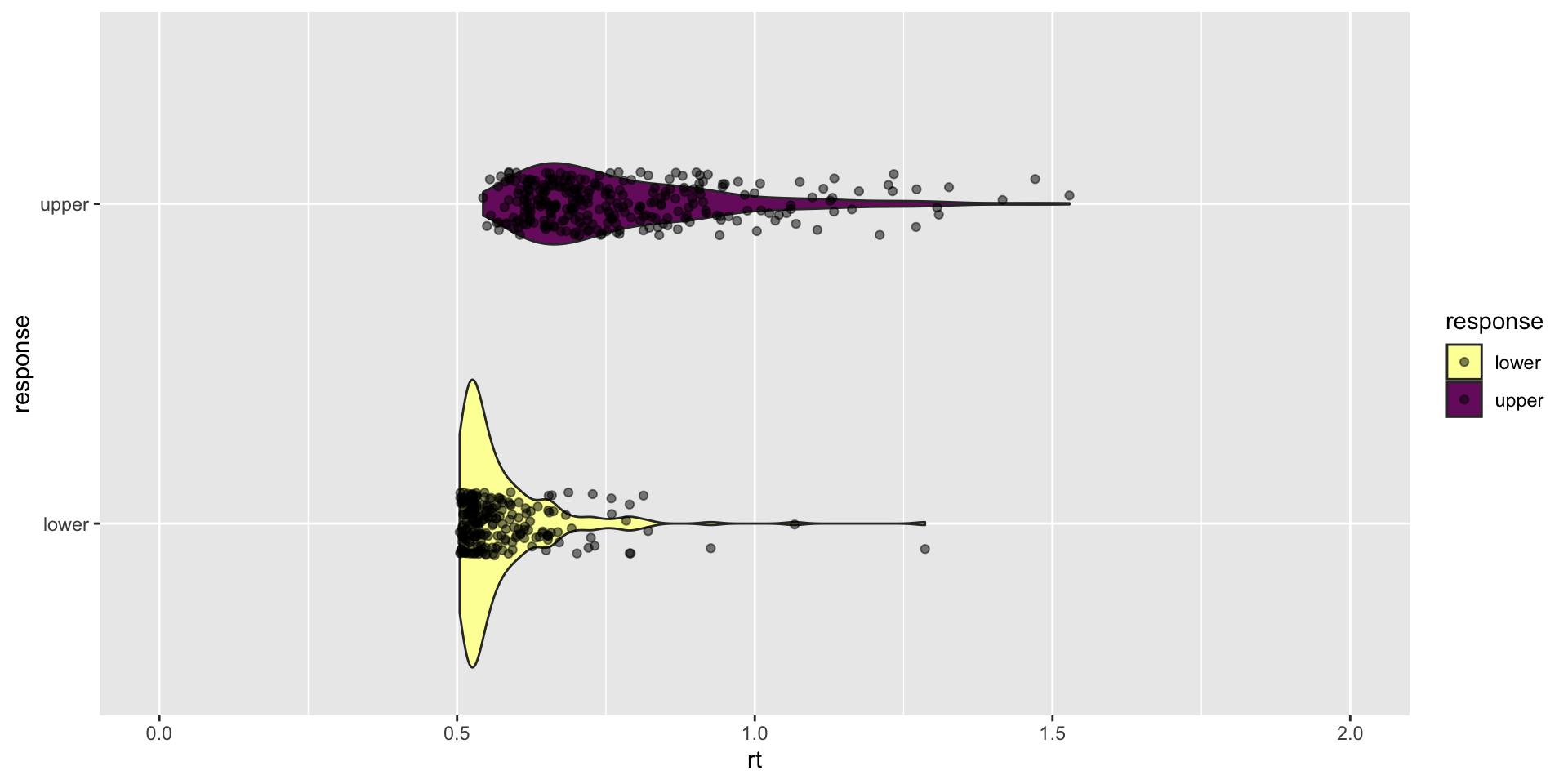
Effect of Bias
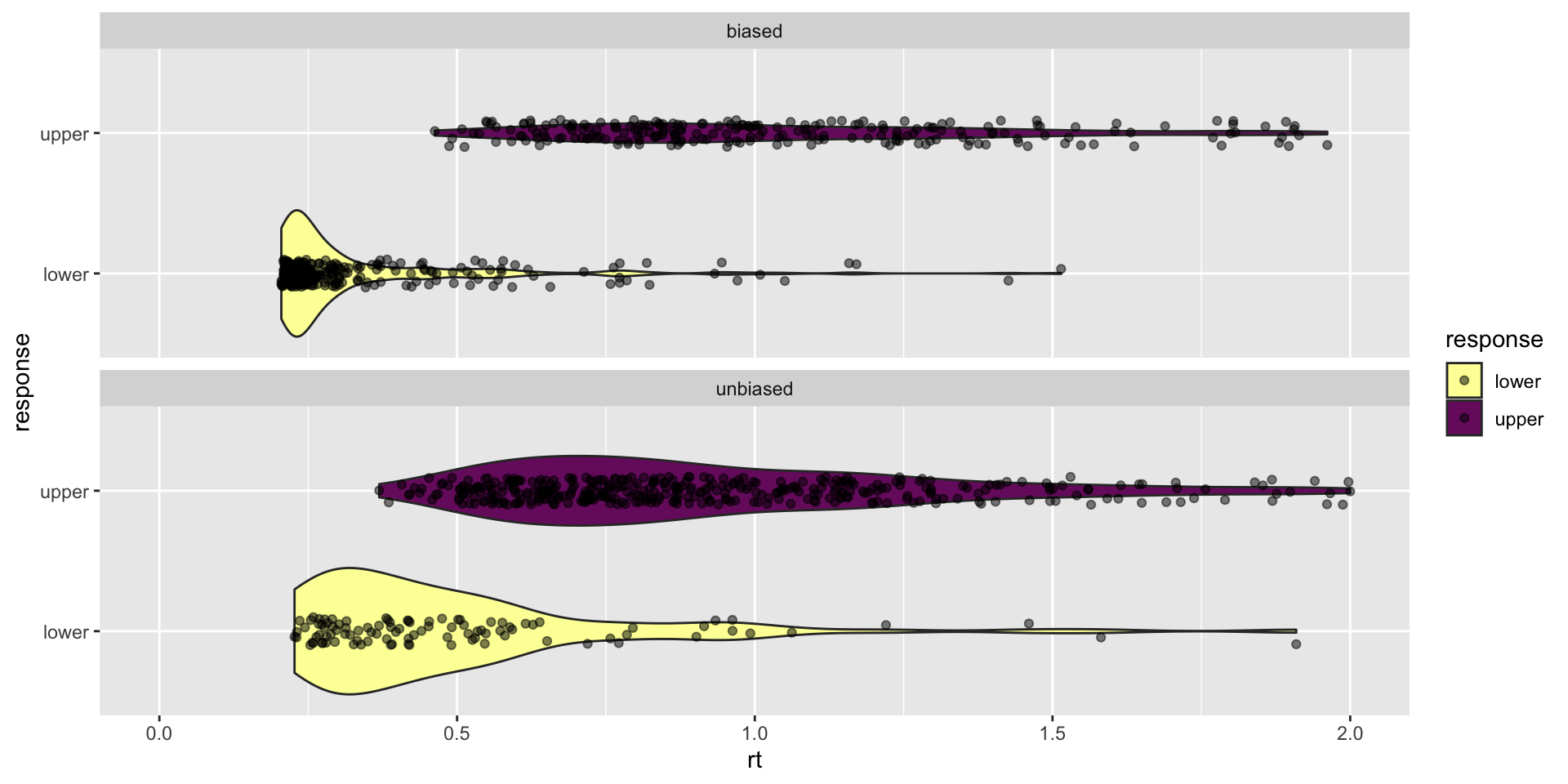
Beispiel Kartenspiel zwischen 2 Spielern
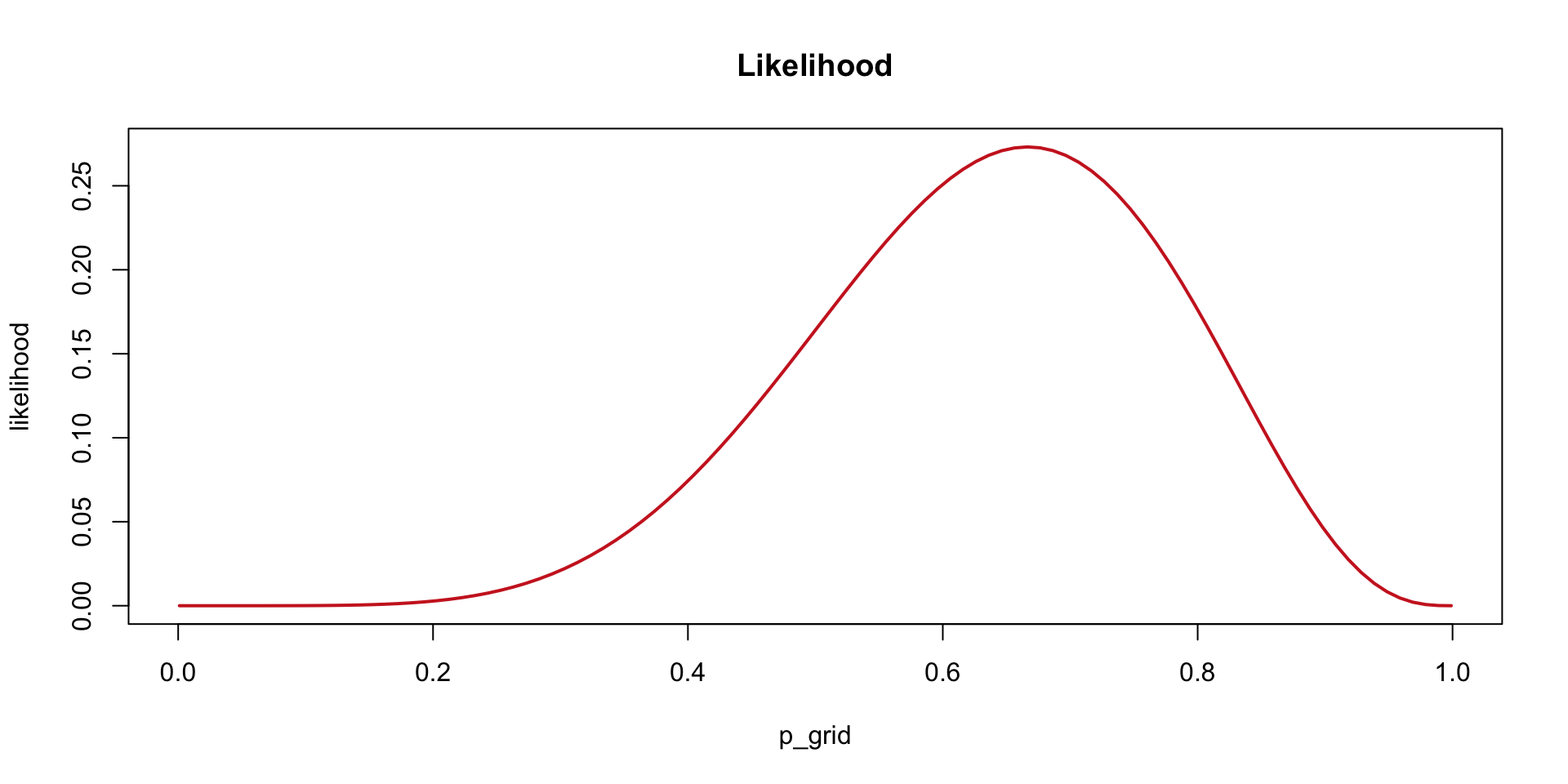
- Index des Parameterwertes, welcher die Likelihood maximiert:
- Parameterwert andiesem Index:
Minimieren
$minimum
[1] 2.530081
$estimate
[1] 0.4799995
$gradient
[1] 0
$code
[1] 1
$iterations
[1] 8