9. Sitzung
Evidence accumulation models: I
Andrew Ellis
Neurowissenschaft Computerlab FS 22
2022-04-26
1
What are decisions?
Decision
Jeden Tag treffen wir Tausende von kleinen Entscheidungen (unter Zeitdruck).
Viele davon sind trivial (z. B. welches Paar Socken man anziehen oder welche Fernsehserie man schauen soll) und automatisch (z. B. wie man den Kollegen morgens begrüsst oder welches Wort man als nächstes in eine E-Mail schreiben soll).
Nach einiger Überlegung muss eine Entscheidung auf der Grundlage der Daten getroffen werden.
Die meisten Entscheidungen im wirklichen Leben setzen sich aus zwei separaten Entscheidungen zusammen: zuerst die Entscheidung, mit dem Überlegen aufzuhören und zu handeln, und dann die Entscheidung oder Handlung selbst.
2
Sequential Sampling
Sequential Sampling
Statistik: Daten (evidence) werden im Laufe der Zeit gesammelt, und der Statistiker muss entscheiden, wann er die Datenerfassung beenden und eine Entscheidung treffen muss.
Der sequentielle Charakter der Entscheidungsfindung ist eine grundlegende Eigenschaft des menschlichen Nervensystems und spiegelt seine Unfähigkeit wider, Informationen sofort zu verarbeiten..
Um die Dynamik der Entscheidungsfindung zu verstehen, konzentrieren sich die meisten Studien auf einfache, wiederholbare Wahlprobleme mit nur zwei (binären) Alternativen.
3
Gesetzmässigkeiten
Gesetzmässigkeiten
Daten von elementaren Entscheidungsaufgaben lassen mehrere gesetzesähnliche Muster erkennen, die jedes Modell der Entscheidungsfindung berücksichtigen muss.
Die mittlere RT ist für einfache Stimuli kürzer als für schwierige Reize..
“Speed stress” verkürzt die mittlere RT, erhöht aber den Anteil der Fehlerrate.
Mittlere RT ist proportional yur Standardabweichung.
Manipulationen, die die Geschwindigkeit der richtigen Antworten erhöhen, erhöhen auch die Geschwindigkeit der Fehlerantworten.
RT-Verteilungen sind rechtsschief, und diese Schiefe nimmt mit der Schwierigkeit der Aufgabe zu.
Bei schwierigen Aufgaben ist die mittlere Fehler-RT oft langsamer als die mittlere korrekte RT - dieses Muster kann durch “Geschwindigkeitsstress”speed stress” umgekehrt werden.
4
Diffusion Decision Model
Diffusion Decision Model
- Das von Roger Ratcliff entwickelte Modell hat seinen Ursprung in Modellen zu den Bewegungen von Partikeln in einer Flüssigkeit, und geht auf Arbeiten von Albert Einstein und Norbert Wiener zurück.
- Binäre Entscheidungen basieren auf der Anhäufung von verrauschten Beweisen, beginnend am Ausgangspunkt und endend an einer Entscheidungsschwelle, die mit einer bestimmten Entscheidung verbunden ist.
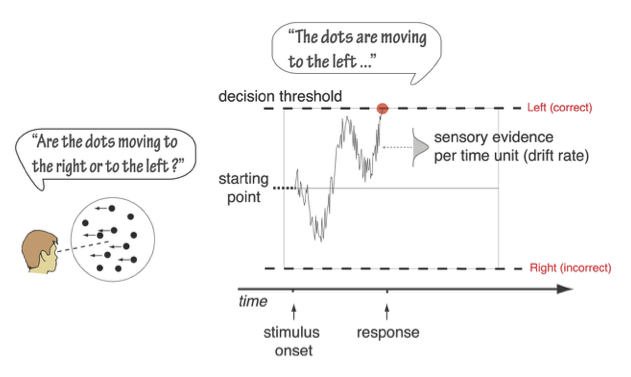
Aus Mulder et al. (2012)
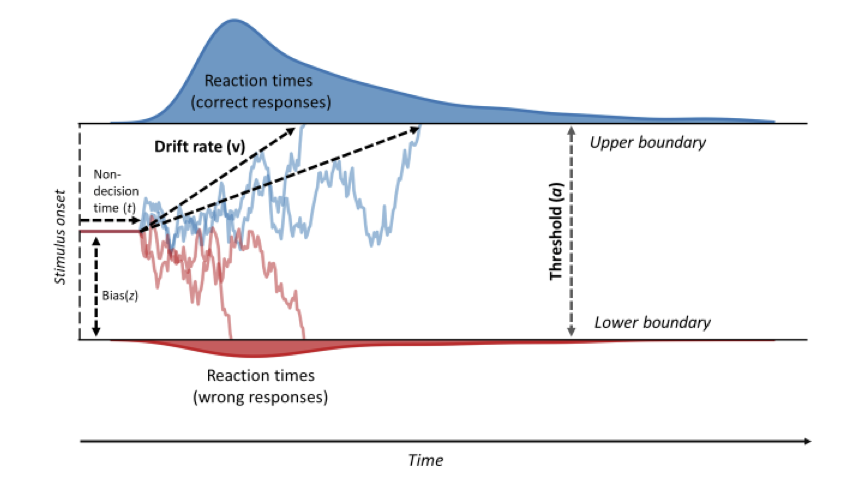
RT Verteilungen
DDM Parameter
Das Modell hat vier Parameter. 1
Drift rate steht für die durchschnittliche Anzahl von Beweisen pro Zeiteinheit und ist ein Index für die Schwierigkeit der Aufgabe oder die Fähigkeit des Subjekts.
Boundary separation stellt die Vorsicht dar; eine größere Trennung der Grenzen führt zu weniger Fehlern (wegen geringerer Auswirkung des Diffusionsrauschens innerhalb des Trials), jedoch um den Preis einer langsameren Reaktion (speed-accuracy tradeoff).
Starting point repräsentiert die a-priori Präferenz für eine der Wahlalternativen.
Non-decision time ist ein Verzögerungsparameter, der die Zeit für periphere Prozesse (Kodierung eines Reizes, Umwandlung der Repräsentation des Reizes in eine entscheidungsbezogene Repräsentation) und Ausführung einer Reaktion misst.
- Gesamtzeit für eine Reaktion ist die Zeit für die Ausbreitung vom Startpunkt bis zur Grenze plus die Non-decision time
Beispiele
Altern: ältere Erwachsene sind oft langsamer als jüngere, machen aber nicht mehr Fehler. DDM Resultate haben gezeigt, dass es nicht immer kognitive Fähigkeiten sind, welche mit dem alter abnehmen, sondern oftmals periphere Prozesse und grössere Vorsicht. Dies konnte in Studien zu numerosity judgments, lexical decisions und recognition memory gezeigt werden.
Arbeitsgedächtnis und IQ: ein höherer IQ geht mit einer grösserern drift rate einher.
Klinische Studien: Patienten mit Angststörungen haben eine höhere drift rate für bedrohliche Wörter/Bilder mit bedrohlichem Inhalt.
Anhand von DDM können Neuowissenschaftler Hirnmessungen mit kognitiven Prozessen assoziieren, anstelle von behavioralen “Effekten”.
DDM Annahmen
- Binary decision making: DDM ist ein Model für binäre Entscheidungen.
Stroop-Aufgabe. Obwohl es mehrere Antworten gibt (eine für jede Farbe), könnte man versuchen, die Genauigkeitsdaten mit dem Diffusionsmodell zu modellieren und dabei unterschiedliche Driftraten für kongruente und inkongruente Versuche zu berücksichtigen.
Continuous sampling: Entscheidungen beruhen auf einem kontinuierlichen Verarbeitung von Daten.
Single-stage processing: Entscheidungen basieren auf einer einstufigen Verarbeitung.
Parameter sind konstant. Das heisst z.B. drift rate kann sich nicht über Zeit verändern.
Fitting Parameters
Wir simulieren nun einen Evidenz Accumulation Process Schritt-für-Schritt. Damit können wir Zufallszahlen generieren.
Um Parameter Fitting zu machen, brauchen wir jedoch die Wahrscheinlichkeitsdichte, d.h. die Wahrscheinlichkeit, die gegebene Grenze in der gegebenen Zeit zu erreichen (gegeben die Parameter).
Dies machen wir in der nächsten Sitzung.
Literature
Voss, A., Nagler, M., & Lerche, V. (2013). Diffusion Models in Experimental Psychology: A Practical Introduction. Experimental Psychology, 60(6), 385–402. https://doi.org/10.1027/1618-3169/a000218
Forstmann, B. U., Ratcliff, R., & Wagenmakers, E.-J. (2016). Sequential Sampling Models in Cognitive Neuroscience: Advantages, Applications, and Extensions. Annual Review of Psychology, 67, 641–666. https://doi.org/10.1146/annurev-psych-122414-033645
Ratcliff, R., & McKoon, G. (2008). The Diffusion Decision Model: Theory and Data for Two-Choice Decision Tasks. Neural Computation, 20(4), 873–922. https://doi.org/10.1162/neco.2008.12-06-420